Masked Sensorimotor Prediction
Given a sequence of camera images, proprioceptive robot states, and past robot actions, we encode the interleaved sequence into tokens, mask out a random subset, and train a model to predict the masked-out content from the rest.
We propose a self-supervised sensorimotor pre-training approach for robotics. We formulate pre-training via a sensorimotor prediction problem. We hypothesize that if the robot can predict the missing sensorimotor content it has acquired a good model of the physical world that can enable it to act. We instantiate this idea through a masked prediction task, similar to BERT and MAE.
Our model, called RPT, is a Transformer that operates on sequences of sensorimotor tokens. Given an input sequence of camera images, proprioceptive states, and actions, we encode the interleaved sequence into tokens, mask out a random subset of the sequence, and predict the masked-out content from the rest. We perform random masking across all modalities and time using a high masking ratio, which encourages the model to learn cross-modal, spatio-temporal representations.
We encode camera images using a pre-trained vision encoder and use latent representations for sensorimotor sequence learning. This enables us to benefit from strong vision encoders trained on diverse Internet images. Compared to prediction in pixel space, using latent visual representations makes the task feasible. Finally, this design decouples the vision encoder from the sensorimotor context length, making 10 Hz control with 300M parameter models feasible on a physical robot.
Real-World Trajectories
To evaluate our pre-training approach, we collect a dataset of 20,000 real-world trajectories using a combination of motion planning and model-based grasping algorithms. Each trajectory is a sequence of multi-view camera images, proprioceptive robot states, and actions. We include classic motor control and robotic tasks, namely, single object picking, bin picking, stacking, and destacking, with variations in object poses, shape, and appearance.
Each trajectory contains camera images from three views
Model Inference
We fine-tune the pre-trained model with behavior cloning (BC) on downstream tasks. During fine-tuning, we construct a model that takes the past sensorimotor inputs of the same context length as in pre-training and initialize it with the pre-trained weights. We replace the input action token in the last time step with a mask token. We only keep the output token that corresponds to the mask input token, and discard all the other output tokens.
We perform inference in the autoregressive fashion. Given a set of sensory observations we first predict an action. We then execute the action and feed back both the action and the new set of sensory observations to the model. We repeat this process iteratively to complete the task.
At inference time, we only provide the mask token for the last action. After we predict an action, we execute it and feed back to the model with the new sensory observations. We repeat this process iteratively until the task is complete.
Transfer to Downstream Tasks
We consider three different tasks for downstream evaluation: picking, stacking, and destacking. We note that all of our policies predict actions in the continuous joint position space. We do not make any domain or task-specific assumptions in the observation space or in the action space. Our policies run at 10 Hz and we show example videos below at 1x.
Outperforms Training from Scratch
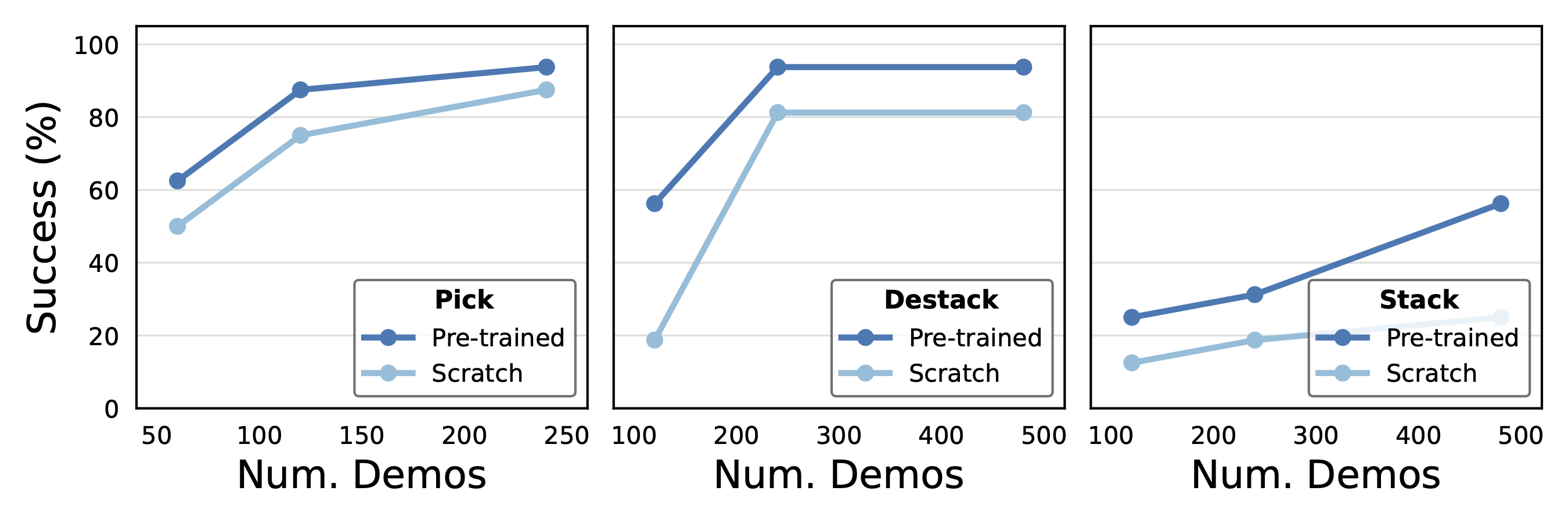
We study the effectiveness of our method by comparing fine-tuning performances with or without sensorimotor pre-training. We consider three evaluation tasks of increasing difficulty: picking, destacking, and stacking. We use unseen and held-out data from the same task for fine-tuning. Below, we show the performance as the number of fine-tuning demonstrations increases. We observe that pre-training leads to consistent improvements over training from scratch, across tasks and data regimes. Moreover, the gains are larger for the harder block stacking task.
Comparisons with training from scratch
Failure Cases
Policies trained with our pre-trained representations are sitll not perfect and can fail in a variety of ways. Here we show example videos of some of the failure cases.
Imprecise pick
Imprecise stack
Misaligned close
Object slip
BibTeX
@article{Rpt2023,
title={Robot Learning with Sensorimotor Pre-training},
author={Ilija Radosavovic and Baifeng Shi and Letian Fu and Ken Goldberg and Trevor Darrell and Jitendra Malik},
year={2023},
journal={arXiv:2306.10007}
}